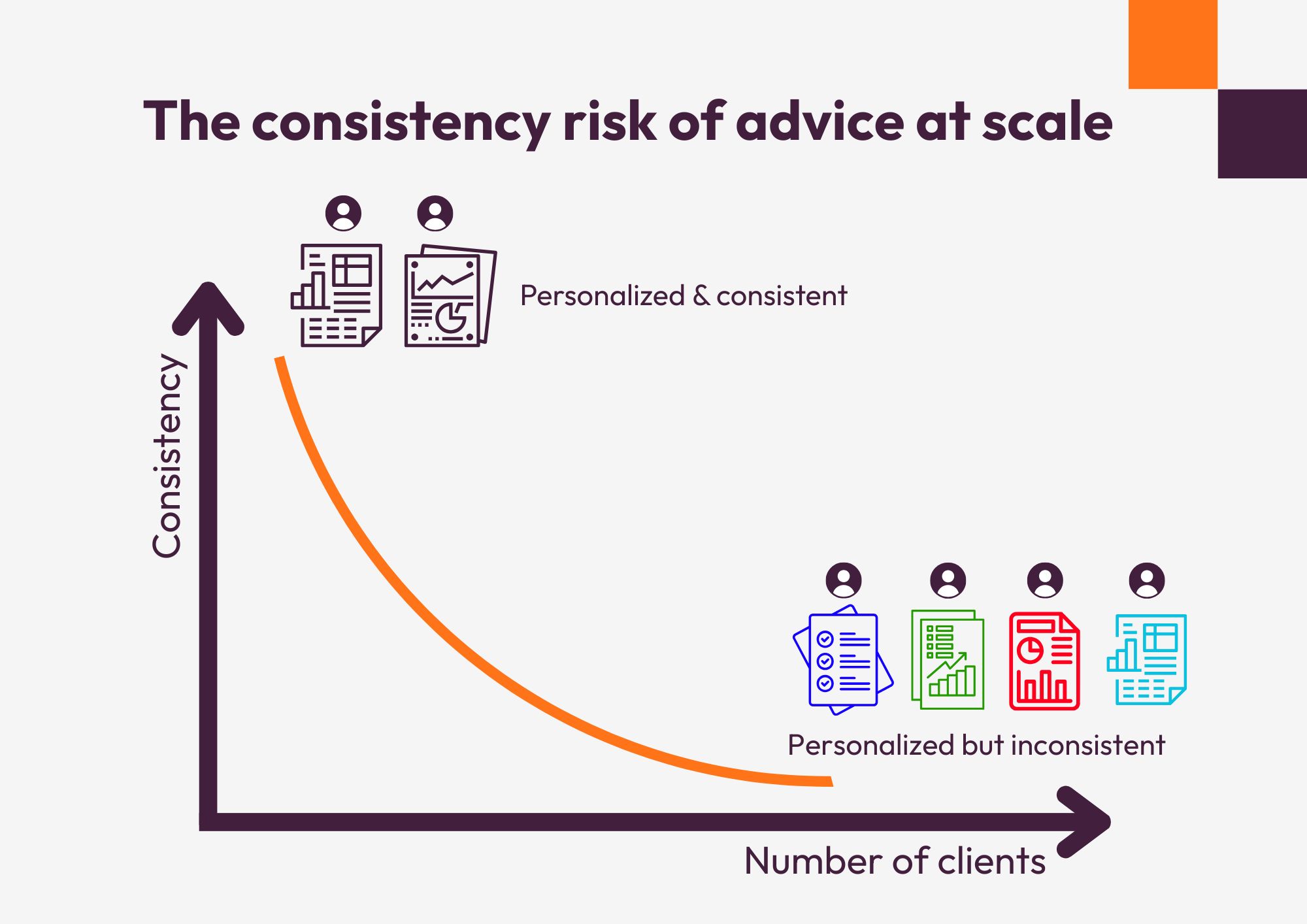
A raw score rarely answers the real question.
Someone can score 72/100 and still ask: “So… is that good?”
Benchmarking exists to answer that question with context:
But benchmarking also has a reputation problem. In many organizations, benchmarks become:
Benchmarking only builds trust when it is designed for interpretation, not competition.




Want to know more?
Subscribe to our newsletter and get hand-picked articles directly to your inbox

Yes. Internal benchmarks (past cohorts, baseline comparisons, segmented peer groups) often provide more actionable context than generic industry averages.
It can, but requires careful structure. Qualitative inputs need consistent coding or scoring frameworks to be comparable.
Not always. Broad visibility can motivate improvement in some cultures and trigger defensiveness in others. Benchmark access should match the purpose and governance model.
Comparing incomparable groups—then treating the difference as performance truth rather than a context mismatch.


About the author:
Jeroen De Rore
As Creative Copywriter at Pointerpro, Jeroen thinks and writes about the challenges professional service providers find on their paths. He is a tech optimist with a taste for nostalgia and storytelling.